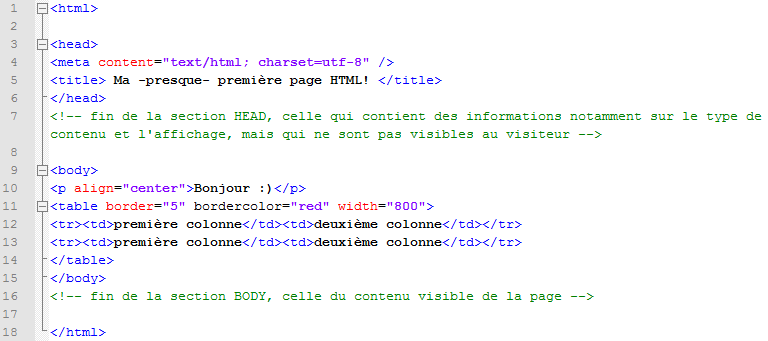
Un aspect important n'avait jusqu'ici pas été pris en compte dans nos scripts: l'encodage de la page html. Dans ce projet, nous sommes amenées à travailler sur plusieurs langues comportant des caractères non-ascii et il est donc capital de pouvoir toutes les traiter sans avoir à spécifier une table de caractères différente à chaque fois. Cette possibilité nous est donnée par utf-8.
Convertir un fichier en utf-8 n'est pas compliqué en soi, mais cette étape en implique bien d'autres puisqu'il faut d'abord savoir de quel encodage on part avant d'appliquer le processus de conversion!
Avant même d'écrire du code, commençons par structurer nos idées. Voici ma démarche détaillée en bon (?) français:
Si l'encodage repéré par file est bien utf-8,... alors on dumpe directement - lynx... sinon, on cherche à savoir si l'encodage repéré est connu d'iconvSi l'encodage est connu d'iconv... alors convertir puis dumper - iconv, lynx... sinon, s'aider des métadonnées htmlSi l'argument charset de la balise meta est bien présente,... alors extraire la valeur de l'argument charsetSi l'encodage extrait est connu d'iconv,... alors convertir puis dumper - iconv, lynx... sinon, échec: encodage extrait inconnu d'iconv.... sinon, échec: encodage non précisé dans le code html.
Ce qui donne en script:


Pour réaliser toutes les étapes décrites ci-dessus, nous nous sommes servies des commandes file, iconv, egrep et lynx que nous détaillons ci-dessous:
- encodage=`file -b --mime-encoding ./PAGES-ASPIREES/$i/$j.html`; (qui précède toutes les étapes et n'apparaît pas dans les screenshots)
Cette commande permet de stocker dans la variable encodage le résultat de la commande file qui, elle, nous donne l'encodage de la page mise en input.
-b (brief) est une option qui rend un output bref, c'est-à-dire sans le nom du fichier. (./PAGES-ASPIREES/1/1.html: text/html; charset=utf-8)
--mime-encoding est une option qui nous donne l'encodage de page sans le type de contenu et sans le nom des arguments. (text/html; charset=utf-8).
[... et voilà comment se débarrasser des cuts.]
- verif_iconv=`iconv -l | egrep -io $encodage`;
La première partie de cette commande nous fournit la liste des encodages connus par la commande de conversion iconv grâce à l'option -l (list). L'output de cette partie est redirigé vers l'input de la seconde partie qui va l'utiliser en contexte. En effet, la commande egrep s'utilise avec la syntaxe suivante: egrep [options] "motif" "contexte/domaine de recherche". Ici, le motif est l'encodage repéré au préalable par file, et les options utilisées, -i (ignore-case) et -o (only-matching) permet de ne pas prendre en compte la casse (ne sait-on jamais...) et de ne récupérer que ce les caractères qui correspondent à ce que l'on cherche.
- lynx -dump -nolist -display_charset=$encodage ./PAGES-ASPIREES/$i/$j.html > ./DUMP-TEXT/$i/$j.txt;
La commande lynx a déjà été expliquée dans l'article précédent. Nous y avons juste ajouté l'option -display_charset qui indique à lynx dans quel encodage il faut écrire l'output de la commande.
- iconv -f $encodage -t utf-8 "./PAGES-ASPIREES/$i/$j.html" > "./DUMP-TEXT/$i/$j-utf8.txt";
Si l'encodage repéré par file ou dans les métadonnées html est connu de la commande iconv, on peut appliquer cette ligne de commande qui va convertir le fichier à partir d'un encodage donné (-f (from code)) à un autre (-t (to code)).
- egrep -qi ".*charset ?=.*" ./PAGES-ASPIREES/$i/$j.html
L'option -q (quiet) permet de ne rien écrire dans le terminal et de ne rien garder en output si le motif n'est pas trouvé dans le contexte. Le motif se décompose de cette manière: "trouver la chaîne de caractères charset, précédée de n'importe quoi (.* n'importe quel caractère à l'infini) et suivie ou non d'un espace ( ?) puis d'un = lui-même suivi de n'importe quel caractère".
- charset_line=$(egrep -m 1 "charset=.*\"" ./PAGES-ASPIREES/1/31.html);
- charset=$(expr "$charset_line" : '.*=\(.*\)\"');
La commande expr permet d'évaluer les expressions, et ici d'utiliser les parenthèses qui extraient directement le motif qui sont incluses dedans. Cette expression régulière illisible et qui nous a donné du fil à retordre se lit donc: "extraire tous les caractères quels qu'ils soient (.*) entre les parenthèses échappées par \ qui sont précédées d'un = lui-même précédé de n'importe quel caractère (.*), et suivies d'un " (échappé aussi par \). [on se comprend, n'est-ce pas?]
Ce qui donne le résultat suivant:

Ce qui donne le résultat suivant: